Software
Most of the softwares can be found in Github
-
VeloAgent: Dissecting and steering cell dynamics using spatially-informed RNA velocity
VeloAgent is a deep generative and agent-based framework for modeling cell state transitions from single-cell transcriptomics data. It estimates gene- and cell-specific transcriptional kinetics, integrates spatial context through local cellular microenvironment simulations, and supports in silico perturbation to study cell fate dynamics. Please check here for details. -
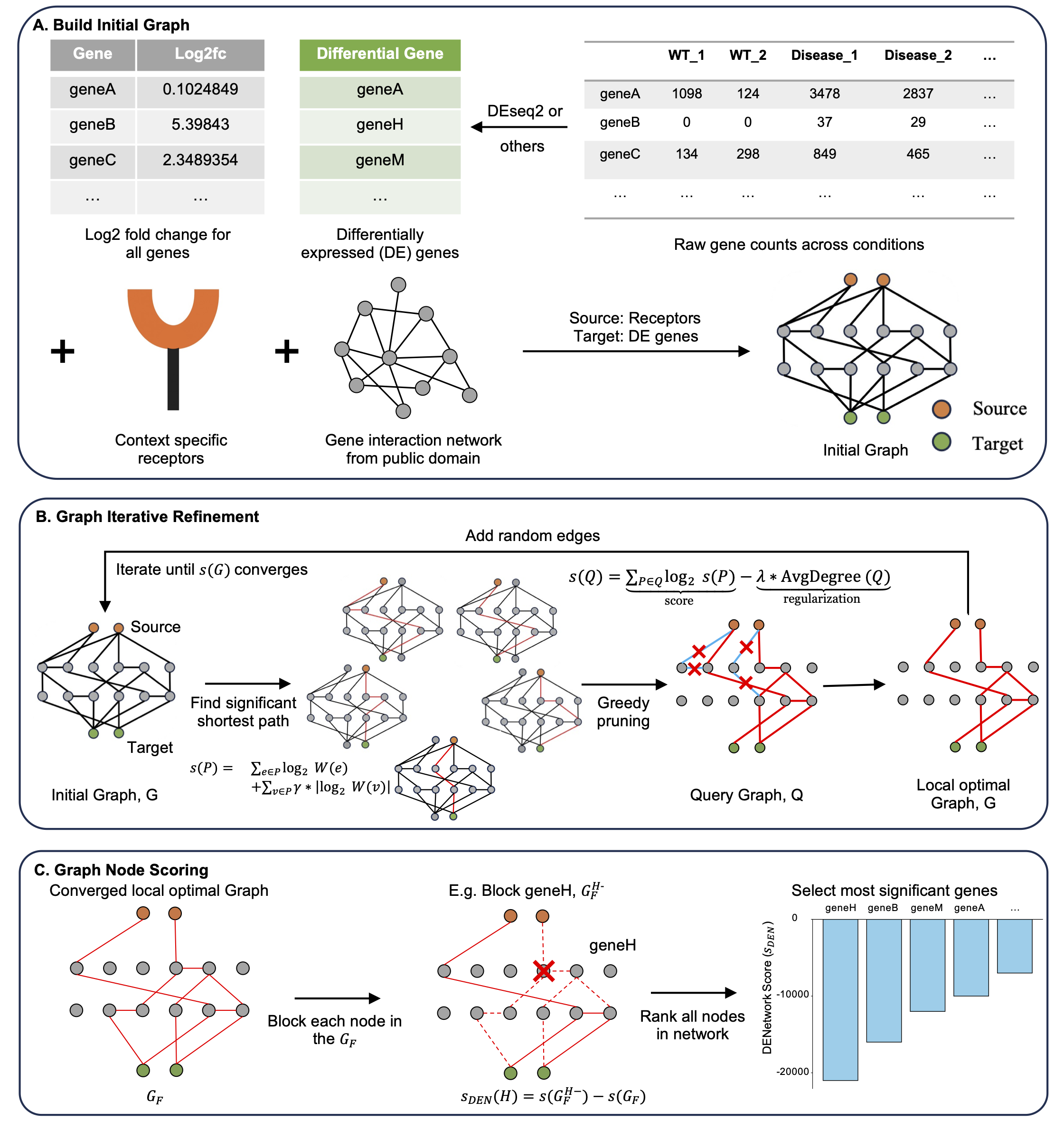
DENetwork unveils non-differentially expressed genes with functional relevance across conditions through information flow perturbation
DENetwork, a network-based approach that prioritizes genes based on their influence on global information flow. Each gene is scored using an in silico knockout strategy that quantifies its impact across the inferred gene network, capturing both DE and non-DE genes with potential functional relevance. Please check here for details. -

SIDISH integrates single-cell and bulk transcriptomics to identify high-risk cells and guide precision therapeutics through in silico perturbation
SCDISH, a neural network framework that integrates the granularity of scRNA-seq with the scalability of bulk RNA-seq. Using a variational autoencoder, deep Cox regression, and transfer learning, SIDISH identifies high-risk cell populations while enabling robust clinical predictions from large-cohort data. Please check here for details. -

scGALA advances graph link prediction-based cell alignment for comprehensive data integration and harmonization
scGALA, a graph-based learning framework that redefines cell alignment by combining graph attention networks with a score-driven, task-independent optimization strategy. scGALA constructs enriched graphs of cell-cell relationships by integrating gene expression profiles with auxiliary information, such as spatial coordinates, and iteratively refines alignment via self-supervised graph link prediction, where a deep neural network is trained to identify and reinforce high-confidence correspondences across datasets. Please check here for details. -
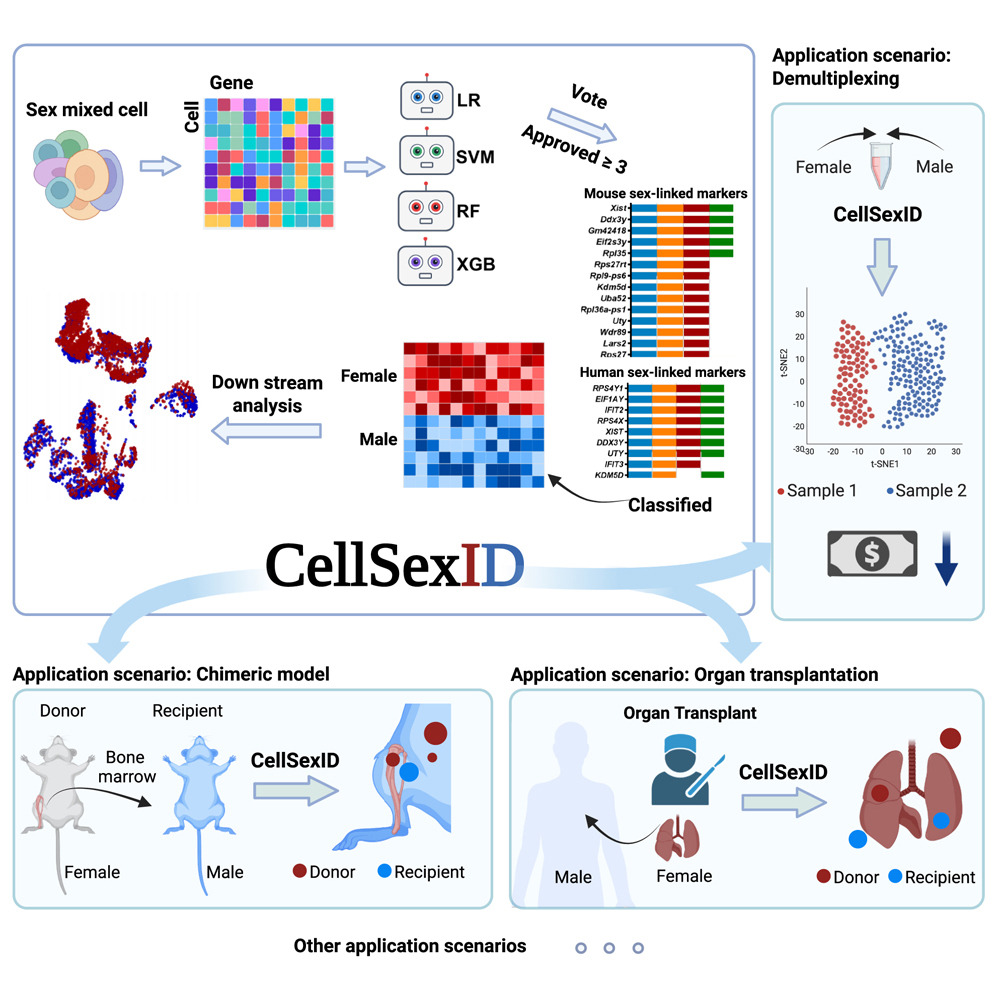
CellSexID: Sex-Based Computational Tracking of Cellular Origins in Chimeric Models
CellSexID is a machine-learning framework that leverages sex-specific gene expression as a natural surrogate for origin in sex-mismatched settings. It identifies minimal, robust marker sets and infers per-cell origin directly from transcriptomes, eliminating the need for genetic engineering or physical labeling. This scalable, cost-effective approach is applicable across tissues, species, and diverse biomedical research scenarios. Please check here for details. -

DOLPHIN: advances single-cell transcriptomics beyond gene level by leveraging exon and junction reads
DOLPHIN, a deep learning method that integrates exon-level and junction read data, representing genes as graph structures. These graphs are processed by a variational graph autoencoder to improve cell embeddings. DOLPHIN not only demonstrates superior performance in cell clustering, biomarker discovery, and alternative splicing detection but also provides a distinct capability to detect subtle transcriptomic differences at the exon level that are often masked in gene-level analyses. Please check here for details. -
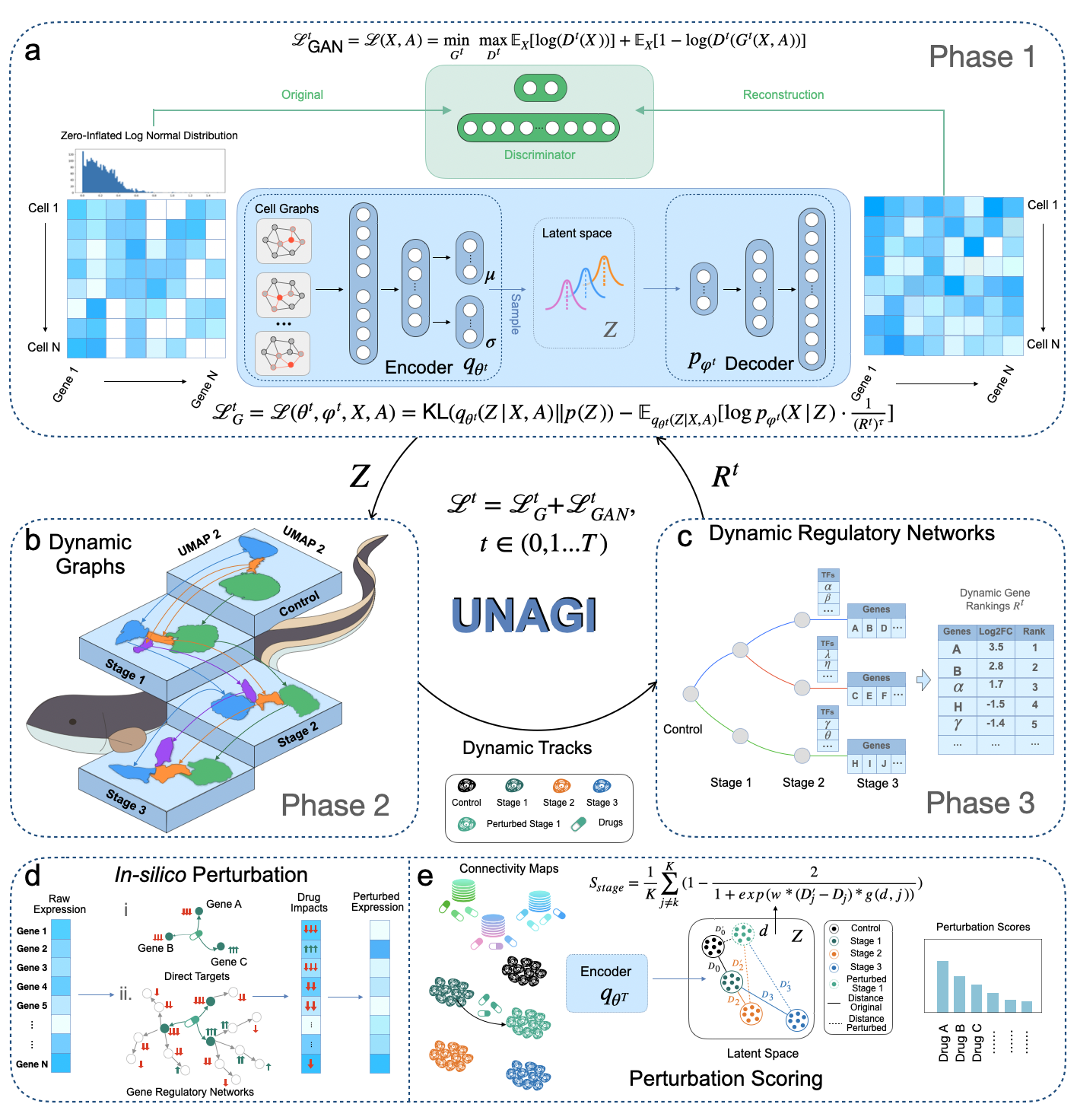
UNAGI: A deep generative model for deciphering cellular dynamics and in silico drug discovery in complex diseases
UNAGI is a comprehensive unsupervised in-silico cellular dynamics and drug discovery framework. UNAGI adeptly deciphers cellular dynamics from human disease time-series single-cell data and facilitates in-silico drug perturbations to earmark therapeutic targets and drugs potentially active against complex human diseases. Please check here for details. -
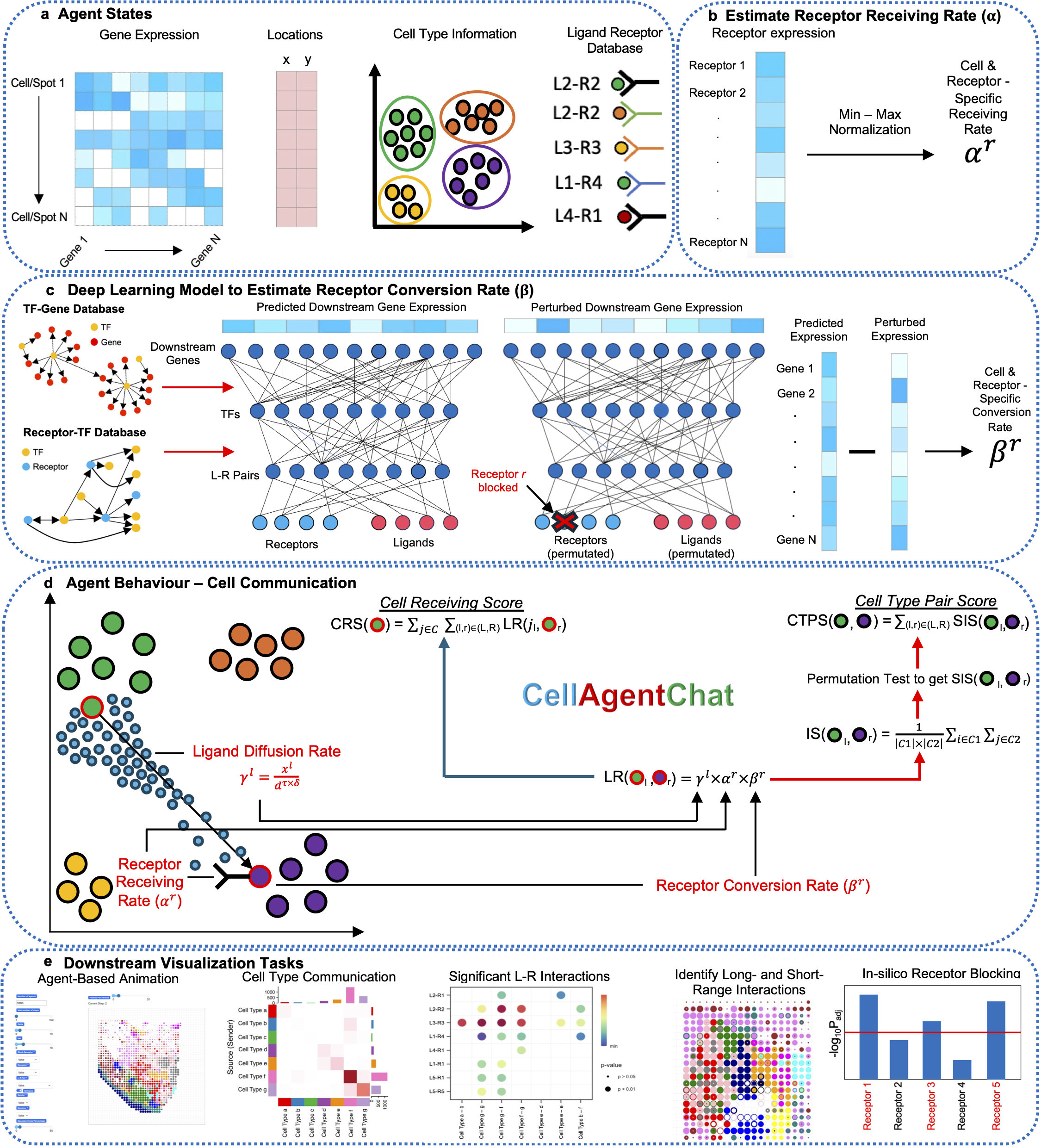
CellAgentChat: Harnessing agent-based frameworks to unravel cell-cell interactions from single-cell and spatial transcriptomics
CellAgentChat constitutes a comprehensive framework integrating gene expression data and existing knowledge of signaling ligand-receptor interactions to compute the probabilities of cell-cell communication. Utilizing the principles of agent-based modeling (ABM), we characterize each cell agent through various attributes, including cell identities (e.g. cell type or clusters), gene expression profiles, ligand-receptor universe and spatial coordinates (optional). We quantify cellular interactions between sender and receiver cells based on the number of ligands secreted by the sender cells and subsequently received by the receiver cells. This process hinges upon three interrelated components: ligand diffusion rate (γl), receptor receiving rate (αr), and receptor conversion rate (βr). Please check here for details. -
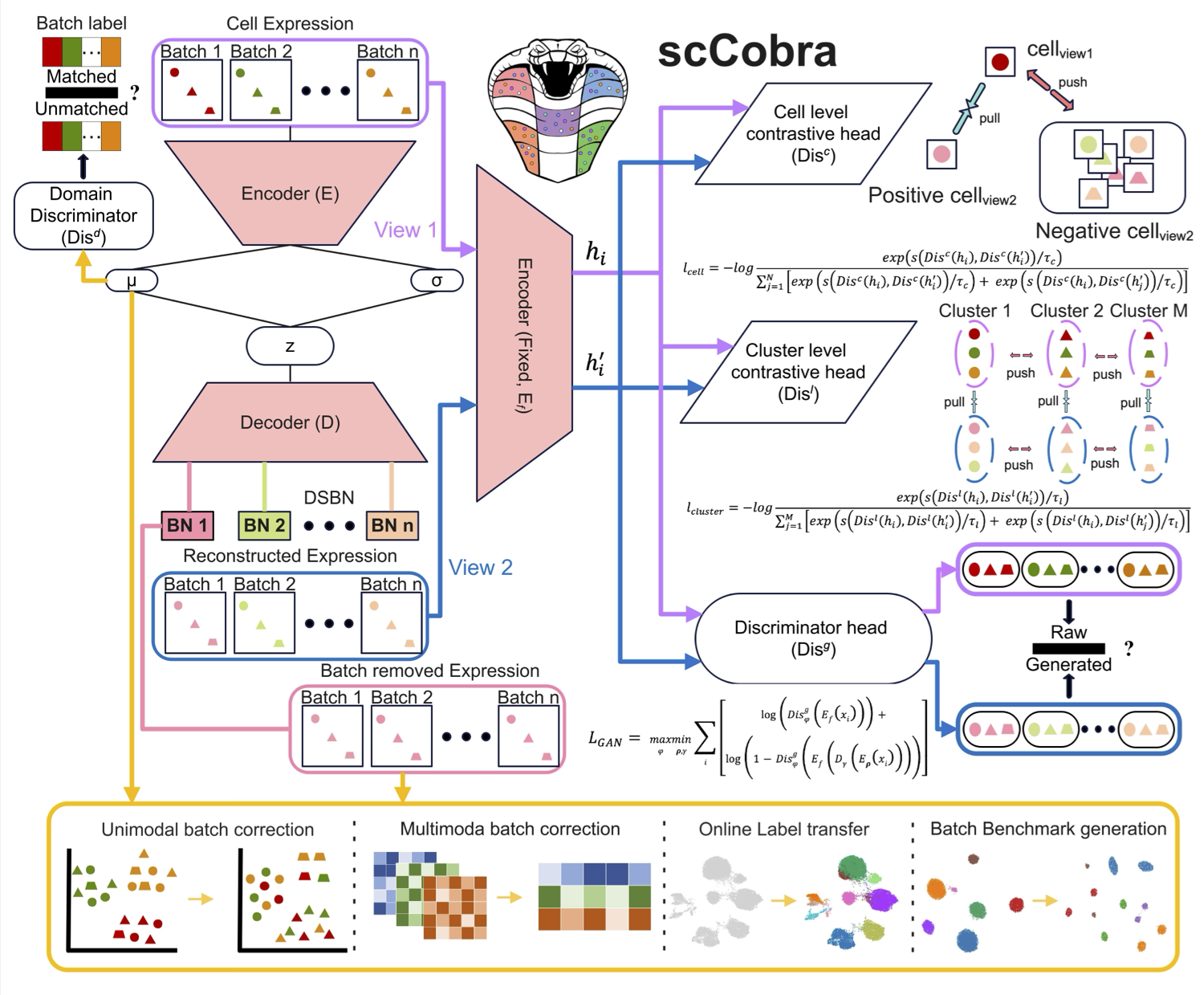
scCobra: allows contrastive cell embedding learning with domain adaptation for single cell data integration and harmonization
scCobra effectively mitigates batch effects, minimizes over-correction, and ensures biologically meaningful data integration without assuming specific gene expression distributions. It enables online label transfer across datasets with batch effects, allowing continuous integration of new data without retraining. Additionally, scCobra supports batch effect simulation, advanced multi-omic integration, and scalable processing of large datasets. By integrating and harmonizing datasets from similar studies, scCobra expands the available data for investigating specific biological problems, improving cross-study comparability, and revealing insights that may be obscured in isolated datasets. Please check here for details. -

MATES: a deep learning-based model for locus-specific quantification of transposable elements in single cell
MATES is a deep-learning approach that accurately allocates multi-mapping reads to specific loci of TEs, utilizing context from adjacent read alignments flanking the TE locus. This development facilitates the exploration of single-cell heterogeneity and gene regulation through the lens of TEs, offering an effective transposon quantification tool for the single-cell genomics community. Please check here for details.
-

scCross: a deep generative model for unifying single-cell multi-omics with seamless integration, cross-modal generation, and in silico exploration
scCross, harnessing variational autoencoder and generative adversarial network (VAE-GAN) principles, meticulously designed to integrate diverse single-cell multi-omics data. Incorporating biological priors, scCross adeptly aligns modalities with enhanced relevance. Its standout feature is generating cross-modality single-cell data and in-silico perturbations, enabling deeper cellular state examinations and drug explorations. More details are in our manuscript.
-

scSemiProfiler: Advancing Large-scale Single-cell Studies through Semi-profiling with Deep Generative Models and Active Learning
scSemiProfiler is an innovative computational tool combining deep generative models and active learning to economically generate single-cell data for biological studies. It efficiently transforms bulk cohort data into detailed single-cell data using templates from selected representative samples. More details are in our manuscript.
-
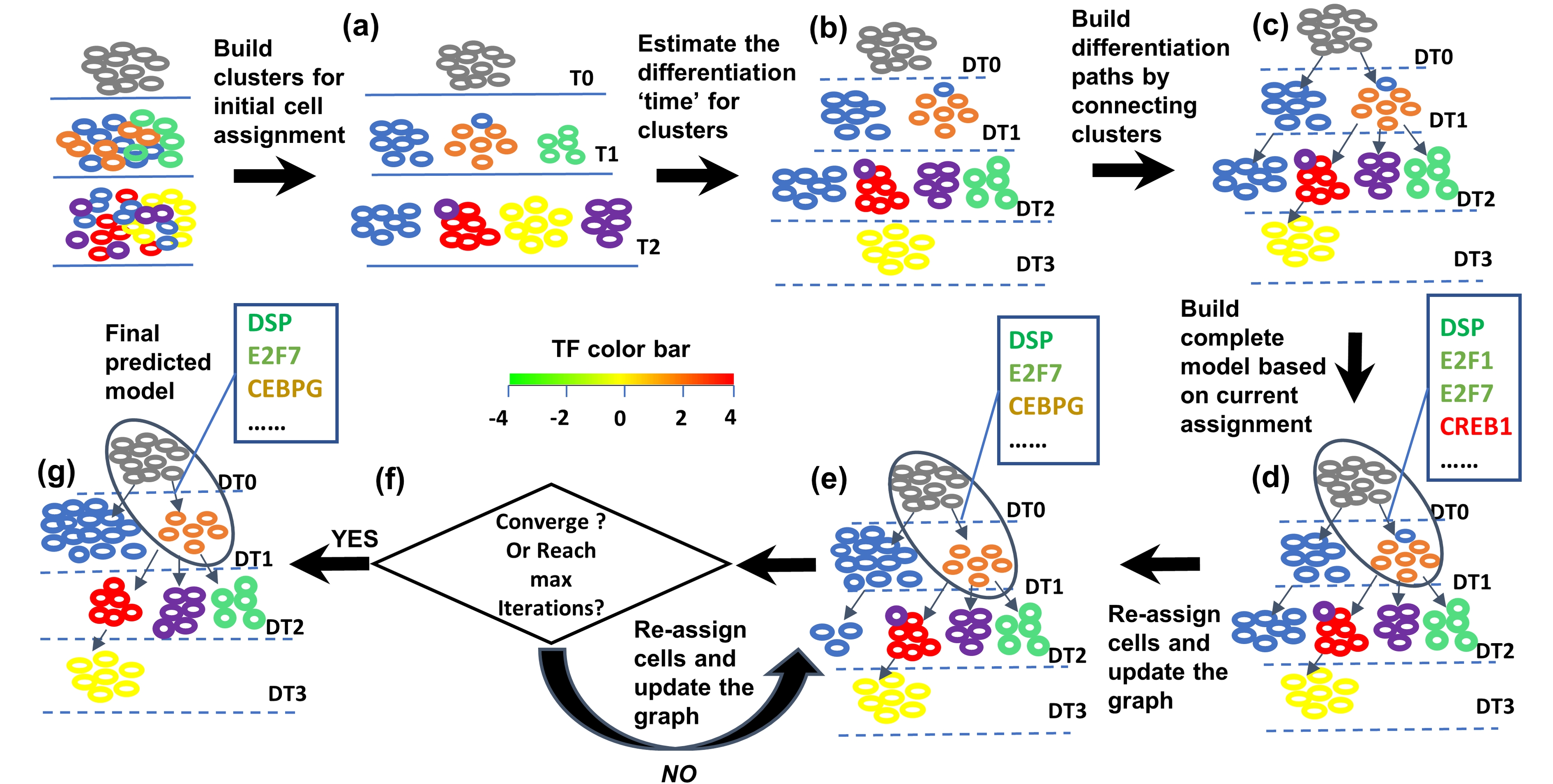
SCDIFF: reconstruct cell differentiation trajectories and underlying regulatory networks from scRNA-seq RNA-seq data
SCDIFF is a package written in python and javascript, designed to analyze the cell differentiation trajectories using time-series single cell RNA-seq data. It is able to predict the transcription factors and differential genes associated with the cell differentiation trajectories. It also visualizes the trajectories using an interactive tree-structure graph, in which nodes represent different sub-population cells (clusters). Please check here for details.
-
TBSP: Trajectory Inference Based on SNP information
Several recent studies focus on the inference of developmental and response trajectories from single cell RNA-Seq (scRNA-Seq) data. A number of computational methods, often referred to as pseudo-time ordering, have been developed for this task. Recently, CRISPR has also been used to reconstruct lineage trees by inserting random mutations. However, both approaches suffer from drawbacks that limit their use. Here we develop a method (named TBSP) to detect significant, cell type specific, sequence mutations from scRNA-Seq data. We show that only a few mutations are enough for reconstructing good branching models. Integrating these mutations with expression data further improves the accuracy of the reconstructed models. Please check here for details. -
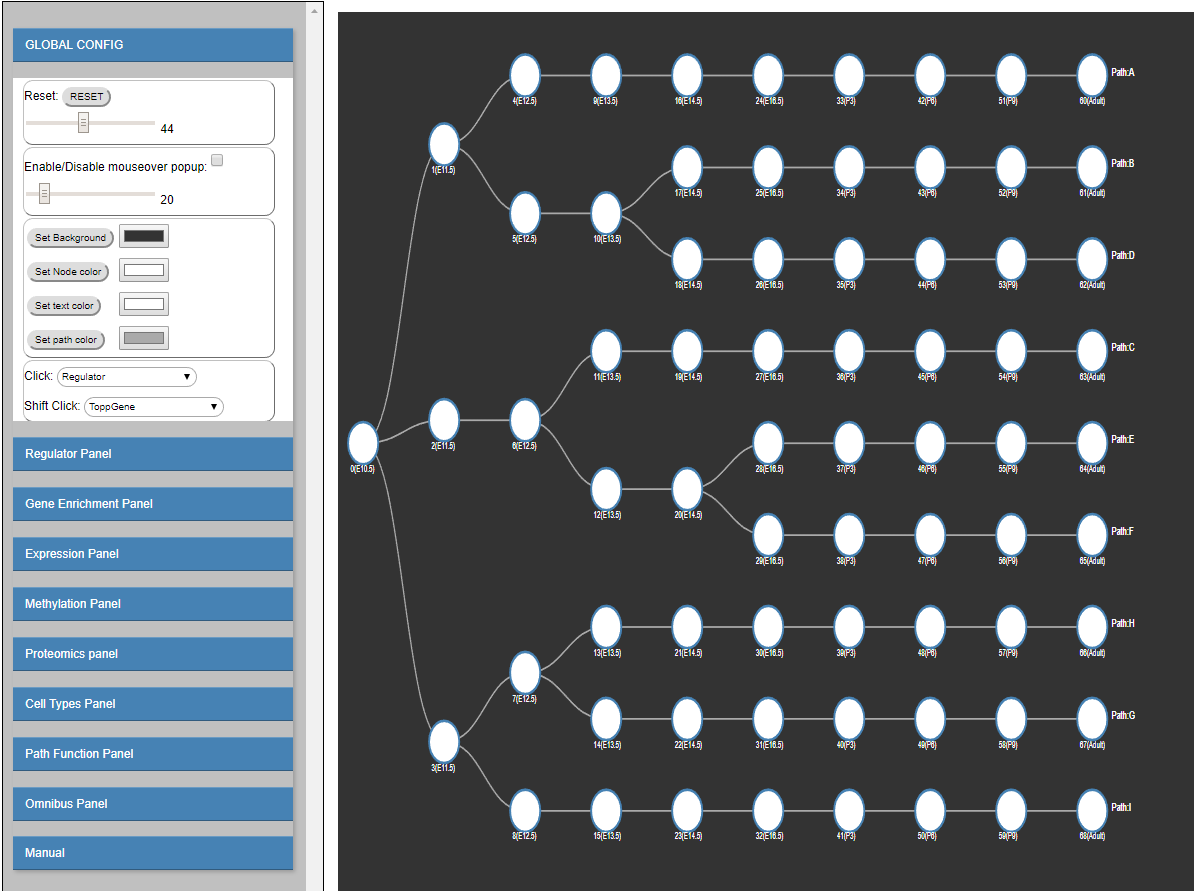
iDREM: interactive Dynamic Regulatory Events Miner
The Dynamic Regulatory Events Miner (DREM) software was initially developed to integrate static protein-DNA interaction data with time series gene expression data for reconstructing dynamic regulatory networks. In recent years, several additional types of high-throughput time series data have been used to study biological processes including time series miRNA expression, proteomics, epigenomics and single cell RNA-Seq. Integrating all available time series and static datasets in a unified model remains an important challenge and goal. To address this goal, and to enable interactive queries of the resulting learned models we have developed a new version of DREM termed interactive DREM (iDREM). iDREM provides support for all data types mentioned above and more. Importantly, it also allows users to interactively visualize a gene, TF, path or model-centric view of each of these data types, their interactions and their impact on the resulting model. We showcase the functionality of the new tool by applying it to integrate several data types from multiple labs for modeling brain development regulatory networks. Please read here for details. -

TarPmiR: a new approach for microRNA target site prediction
The identification of microRNA (miRNA) target sites is fundamentally important for studying gene regulation. There are dozens of computational methods available for miRNA target site prediction. Despite their existence, we still cannot reliably identify miRNA target sites, partially due to our limited understanding of the characteristics of miRNA target sites. The recently published CLASH (cross-linking ligation and sequencing of hybrids) data provide an unprecedented opportunity to study the characteristics of miRNA target sites and improve miRNA target site prediction methods. Applying four different machine learning approaches to the CLASH data, we identified seven new features of miRNA target sites. Combining these new features with those commonly used by existing miRNA target prediction algorithms, we developed an approach called TarPmiR for miRNA target site prediction. Testing on two human and one mouse non-CLASH datasets, we showed that TarPmiR predicted more than 74.2 % of true miRNA target sites in each dataset. Compared with three existing approaches, we demonstrated that TarPmiR is superior to these existing approaches in terms of better recall and better precision. Please read here for details.